
During the early days of my career as a Data Scientist, I had the opportunity to co-create with businesses in various industries on a wide range of projects. I was thrilled to apply the concepts I had learned in school to real-world scenarios. Finally, I was embarking on a journey where I could make an impact on the technological landscape of massive firms.
I’ll be the first to admit that those early-career projects were not always successful. On the contrary, some of them were utter failures. It shouldn’t come as a surprise to any of you that applied Data Science projects can pose immense challenges on both a technical and human level. I know first hand… Let me tell you a story from the beginning of my career as an AI consultant.
How to kill AI ambition for a whole department
At Telecom Inc., a newly-hired Data Science team just developed their first proof of concept: they will now be able to target churners with an unprecedented precision during their upcoming digital marketing campaign. The team just reported their model’s performance to their manager by showing all sorts of relevant technical performance metrics. It even included a confusion matrix and an ROC curve. Their manager was impressed, but was also slightly confused by the use of new statistical language and skeptical of the developed engine. Ultimately, she was hesitant to allow a statistical model to administer a part of the marketing process of her business.
Her fundamental question for the team was: “How can I trust that the model will keep delivering the same results once in production?” After much consideration, deliberating on the risks vs. the rewards, she decided to take a leap of faith and implement the model. After all, the team did prove that the model could perform on new and unseen datasets.
What’s next?
- The costly process of deploying the model into production
- Onboarding a new data engineer.
- The high-end integration process of utilizing the model’s result into their operation
- Training the marketing staff to use the predictions
- Automating the process of sending targeted ads, thereby spending another hefty amount on this whole operation.
A lot of time, money and hope went into this leap of faith, but unfortunately, the model underdelivers. The promised performance is far below the expectations. In many ways, this was a traumatic experience for the whole organization: all those processes and investments squandered in vain. As a result, the manager reverted to her previous traditional processes and continued to avoid anything related to industry buzzwords like Machine Learning or Artificial Intelligence again.
Does this story seem familiar to you? It’s not unique to us. Many companies attempt to innovate and improve their processes only to recoil back to old ways when things become shaky. The thing is, the project could have been successful, if fundamental steps had been taken to ensure that the model’s performance would not degrade once in production. The manager might then have earned more trust in the model and perhaps pursued the necessary efforts to make the project a success.
What can go wrong with our ML models in production?
A myriad of factors can disrupt a model’s performance, the primary challenge being to identify the exact factor affecting your model. On the one hand, the relationship between ML models’ inputs to output is intricate and misunderstood. On the other hand, models are most often positioned in a non-stationary environment: a model’s input is subjected to change form (distribution) through time. Another important question is: When a bug occurs, or the performance degrades, how can we evaluate the causes? To answer this, here are three different concepts that can hopefully provide some insights into the problem:
- Feature bias
- Model robustness
- Data drift
Let’s dig into each one!
Flaws in reasoning – Feature contribution
Most ML models are driven by a complex set of rules which are often unknown and misunderstood. Normally, these rules contain some important inherent flaws which may be obscure to their users. For instance, a model might be trained on some frequent patterns that aren’t replicable once the model is deployed in production.
A great example of this phenomenon is addressed by Daphne Koller in her NY Times article. Professor Koller contemplates that a computer vision model trained and tested upon X-ray images taken from the repository of a certain hospital for the detection of a certain disease, can later predict the disease using all future X-ray images inputted from patients. Of course, this well-trained model may exhibit reduced performance once it’s exposed to the images taken from another hospital, which it may not have encountered during its training phase.
In the previous example of Telecom Inc., it’s quite possible that the model relied on the features that only represented the temporal information (e.g., sales during the month of October) due to a specific promotion which was in place during October alone. Based on this information, we cannot guarantee that our model will perform in the same manner when the promotion is no longer active.
Similarly, many additional flaws can arise from the patterns learnt by an ML model. To name a few:
- Only a few features could be responsible for explaining most of the output’s variance. Consequently, any unexpected variations in those particular features may create drastic changes in a prediction.
- If the importance attributed to certain features is at odds with business knowledge or common sense then the model will most likely not perform well in production. Your model has likely not understood well the relationship in the data, and won’t be able generalized to other situations. i.e.: If our most important feature for our churn model described before would have been the size of our client’s feet, we would have to expect problems in production.
- Any fundamental changes in the feature importance may indicate the presence of data drift. Therefore, feature importance should be closely monitored.
These issues can be avoided by estimating feature contributions and using an appropriate testing process.
Many model agnostic frameworks, such as SHAP and LIME, allow a user to acquire a comprehensive understanding of the relationship between each variable with the output of the model. These frameworks allow their users to identify the most imperative features required by a particular model. The outputs of these frameworks, in terms of identification of important features can be extremely useful to ensure the quality of a model, and address the above-mentioned problems.
Make sense? Ok, let’s carry on with model robustness!
Stress test – Model robustness
In some cases, we may not know how our models will respond to the unexpected inputs: e.g., a previously unseen combination of feature values might trigger the model to predict something ludicrous. Moreover, it’s entirely possible that a slight change in the input(s) might spark an undue variation in the output, especially if the model had previously overfitted the known data.
Consider this image:
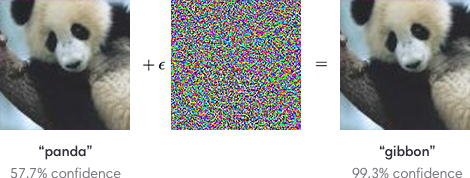
The example presented in Figure 1 shows how a negligible change in data has completely altered the model’s prediction. Yikes! This type of problem can arise in various other ML problems. For instance, it would be possible to corrupt a ML model that detects spam emails by slightly changing the words used in the email(s).
Not to worry. We can avoid such issues by making sure that our model is robust to random and adversarial noise.
We define random and adversarial noise robustness as the model’s resilience to slight variations in the input. In case of random noise, it’s self-explanatory that the distribution of the altered input is a random transformation of the data. As for the adversarial noise, the transformation in the distribution originates from an adversarial attack. That is a perturbation in the inputs in the direction that generates the greatest degradation in the model’s performance.
In both cases, we wish to better understand how our model will react to those alterations. Our primary objective is to assess the chances of our model’s failure once deployed in the production process, when exposed to slightly different and unseen inputs. By observing the model’s loss under such circumstances, we can better evaluate whether our model is sensitive to such changes.
There are some techniques to ensure that our model can be resistant to adversarial attacks or random noise perturbation. In particular, these techniques include adversarial training and addition of random noise to a model, which can effectively improve model performance.
On to data drift!
The inevitable – Data Drift
In ML, Data Drift is a scenario when the data provided to the model’s distribution at the production phase is entirely different from the one utilized during the training and testing phases. It’s often a stretch to assume that the testing data is representative of the data inputted to the model during production. Many environments are prone to the rapid changes that would disrupt a model and affect its performance. Therefore, we should find ways to avoid problems related to data drift.
Primarily, the Data Drift problem can arise in various forms. The most obvious scenario is when the distribution of a single feature changes. Going back to our Telecom Inc. problem, our model’s performance might reduce when 5G adoption begins disrupting old data consumption trends, or Covid-19 drastically increases home internet consumption. Consequently, it’s necessary to assess whether this change will affect the model’s performance.
Many indicators allow us to evaluate the Data Drift issue, such as the Population-Stability-Index or a Kolmogorov-Smirnov test. Both of these non-parametric tests evaluate if the distribution has been replicated for a certain feature. This allows the user in a quality assurance process to either retrain the model without using the drifting features.
What are the current practices, flaws, and improvement possibilities of model validation?
In my earlier example at Telecom Inc., the minimalist methodology employed by the Data Scientist failed to validate the robustness of his model. Evaluating the performance of his model with the unseen data was simply not enough to guarantee a lasting performance. Although the Data Scientist tested his model on a comprehensive test dataset, and monitored its performance on a daily basis, why were both of his tests insufficient and unsuccessful?
Well, both these methods have a limited scope – they cannot evaluate those scenarios which can assure how the model will respond to a different dataset after its deployment in a production process. These tests do not allow a Data Scientist to predict the potential risks that would affect his model’s output quality: they are simply not proactive.
What can we learn from the existing Quality Assurance approaches?
Common Quality Assurance (QA) practices in software development can perhaps inspire ML practitioners to develop more robust models. Usually, most software developers know that they do not have full control over the way users of other programs will interact with their own programs. As a result, they use tests to corner their programs into expected and unlikely scenarios, resulting in failure(s). By using these tests, software programmers can make their software more robust to diverse eventualities. By using these tests, software programmers are making their software more robust to diverse eventualities.
A good practice for software developers is to test each function of their software with different inputs. Why? In order to validate whether the resulting output of a given function is the expected one. Of course, in order to test all the functions, software developers must comprehend the entire logic of their codes. Therefore, programmers will often run these tests many times before deploying a new version of their code. It sounds like a hefty process, and it is. But this is how you achieve success. Slow and steady…
So, what if Telecom Inc., had followed a proper validation process before launching the model into production? They likely would have caught the model’s flaws before taking that leap of faith and deploying the model. Consequently, the team would have been able to deploy a more reliable model that would not have been subjected to failure when confronted with the real world.
We’re here to help
At Snitch AI, we are currently helping Data Scientists do just that. We’ve automated a series of tests related to model explainability, model sensitivity (robustness), and Data Drift. The analysis results are easily interpretable and usable to better understand, improve and monitor your model’s performance.
References:


